






.jpeg) Jörn Kuhlenkamp
Jörn Kuhlenkamp
1 min read
Create Smarter, More Reliable Software-Defined Vehicles With AWS
Imagine a leading automotive manufacturer on the verge of launching its latest model - a cutting-edge, software-defined vehicle (SDV) designed to...

Data-driven decision-making is crucial for the dynamic automotive industry. Automotive Original Equipment Manufacturers (OEMs) are increasingly adopting innovative technologies to gain a competitive edge and extract maximum value from their data.
Serverless computing is an innovative technology that has emerged as a powerful cloud computing model. It promises to allow developers to focus less on operations and more on provisioning available, scalable, and cost-effective data-driven applications efficiently.
Can junior developers use serverless computing with language models like GitHub Copilot or ChatGPT to create production-ready data-driven applications? Although our initial response might be no, this article delves deeper into the reasons why serverless data-driven application engineering requires interdisciplinary skills and an understanding of the application domain to leverage its promises.
To that extent, we will explore concrete examples to show how OEMs can harness the benefits of serverless computing to drive their operations and strategies forward.
Application examples make a general discussion tangible. Hence, they are highly valuable for deep-diving into the peculiarities of data-driven applications for the automotive industry. To illustrate this, we use a custom data-driven application for vehicle testing called DiTics. Vehicle test engineers conduct analyses such as "Emission and Energy Analysis" or "Noise Vibration Harshness Analysis" as part of the vehicle development process or legally required car acceptance processes based on EU law.
Test engineers face increasing challenges when it comes to analysing test run files. DiTics is a tool that can handle test run files in various data formats, including XLSX, Parquet, and CSV, and industry proprietary data formats, like MDF and ATFx. DiTics supports manual test run file uploads, as well as a range of industry-specific connectors, and can handle test run files of varying sizes, from KBs to GBs. Vehicle test engineers can also take advantage of a large number of batteries and analysis programs to meet their custom needs. Moreover, DiTics was built keeping the high data protection needs of OEMs in mind.
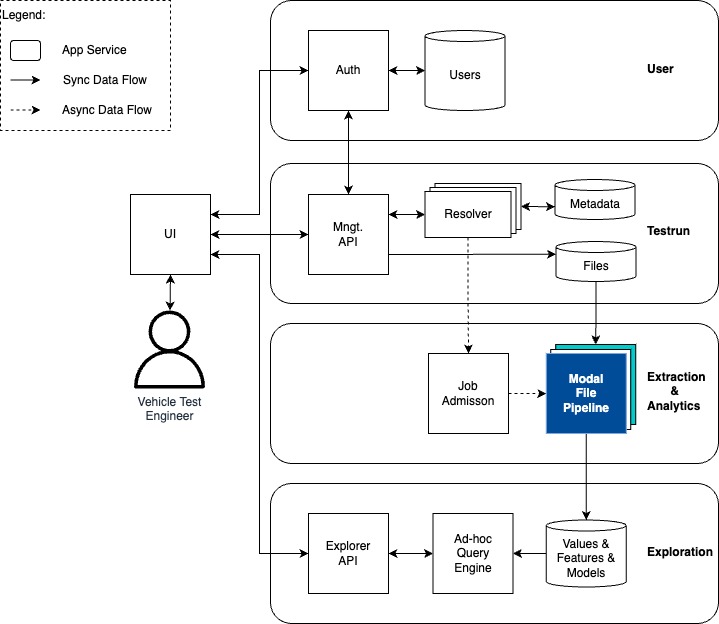
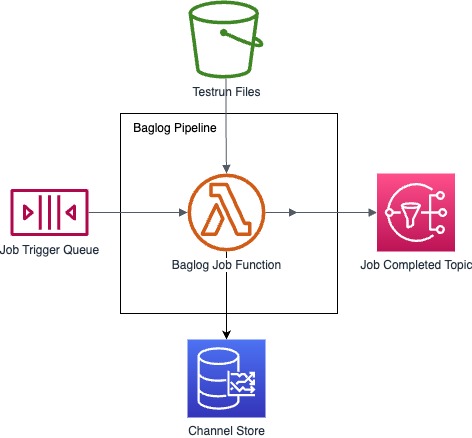
Figure 1 shows the high-level architecture of DiTics. Some details are omitted for readability. Vehicle test engineers interact through a unified user interface (UI) with four backend services. One service processes test run files in a data lake through asynchronous jobs using different pipelines. We zoom into two pipelines to process two different test run file types. The backlog test run files contain a summary and metadata for a test run. The measurements test run files contain high-resolution time series data for a test run. We refer to the corresponding pipelines as (i) modal and (i) measurement pipelines.
Before we look into the system design of both pipelines, we compare the characteristics of two example test run files that the pipelines process: (i) a modal test run file and (ii) a measurement test run file. While the test run files are concrete examples, the main takeaway is that test run files can significantly differ, e.g., regarding their contents, file types, and file sizes.
|
Characteristic |
Modal |
Measurement |
|---|---|---|
|
File type |
xlsx |
MF4 |
|
File size |
~15 MB |
~250 MB |
|
Encodes channels |
> 300 |
> 1000 |
AWS provides a range of serverless cloud services, including AWS Lambda, S3, DynamoDB, and AppSync. In this context, we explore various serverless solution architectures for implementing pipelines. We also create simplified versions of the modal pipeline that maintain the key elements of the original application example and workload. While we give quality indicators for jobs in terms of job timeliness and monetary costs, we do not conduct full benchmarks but rather report on anecdotal measurements for better illustration. We deem this approach feasible as differences are typically in an order of magnitude.
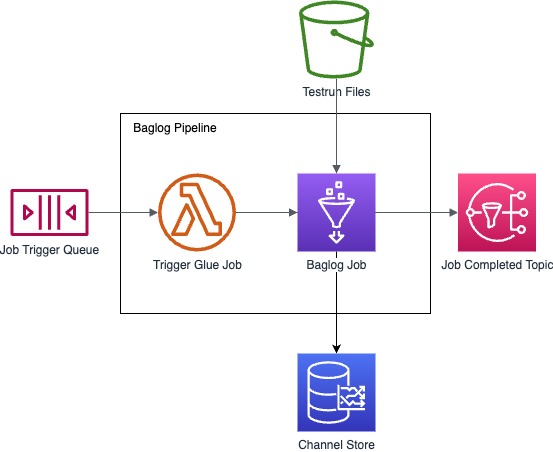
Before diving into the individual solution architectures, we discuss architectural characteristics shared by all. Incoming jobs reside in a SQS queue. On job completion, a message is pushed to a corresponding SNS topic. An S3 bucket serves as a data lake that stores test run files processed by the pipelines. Processed channel data is pushed to a time series database. With this out of the way, we discuss the first solution architecture building on AWS Glue.
The first solution centres around AWS Glue, which AWS prominently advertises as an ETL tool. Currently, AWS Glue does not support the invocation of a job with a direct integration with SQS. Therefore , we integrate both services using an additional Lambda function that pulls messages from the SQS queue and invokes Glue jobs.
With detailed knowledge of Apache Spark, the implementation effort for the solution is low in less than a day. Glue’s cost model for running ETL jobs is based on DPU hours, which is a result of a job's computing resources and runtime.With detailed knowledge of Apache Spark, the implementation effort for the solution can be completed in less than a day. Glue's cost model for running ETL jobs is based on DPU hours, which is a product of a job's used computing resources and runtime. Assuming no performance optimisations and selecting the minimum resource configurations for worker instances executing the job, a job processing a single modal test run file can be completed in approximately 180 seconds, consuming around 0.15 DPU hours. This results in a price tag of roughly 0.0700 USD.
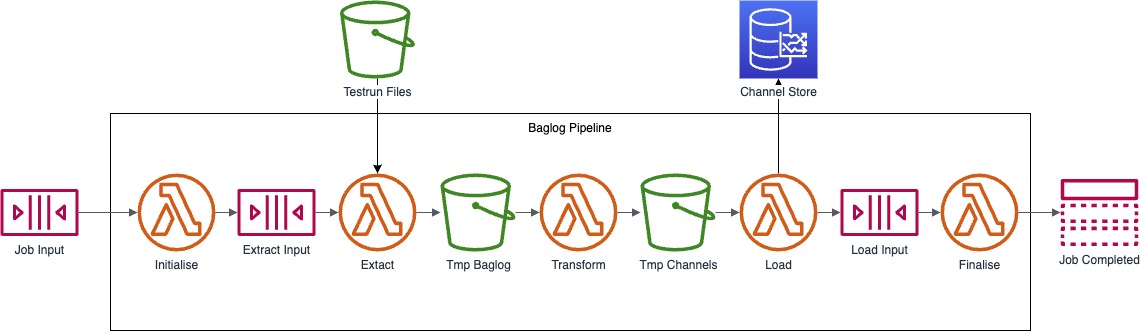
The second solution architecture (see Figure 5) builds on AWS Lambda. We refer to it as Multi-Function because it deploys different job stages using five individual Lambda functions. AWS recommends that a Lambda function does not invoke another Lambda function directly. Hence, this solution architecture uses two additional SNS queues. As the size of intermediate data exceeds limits for message sizes, we store intermediate data in S3 and use event notification to integrate downstream Lambda functions.
The anecdotal execution costs for processing a single test run file with this solution architecture is around 0,0005 USD including AWS Lambda, SQS, and S3 costs. We observed the pipeline executing in 17 seconds.
This solution architecture implies limitations. It raises the question of how to exchange meta-data for the job between Lambda functions integrated through S3. While one option is mixing test run file data with job metadata inside the same files stored in S3, we avoid this due to better separation of concerns. Another common variant of this approach is
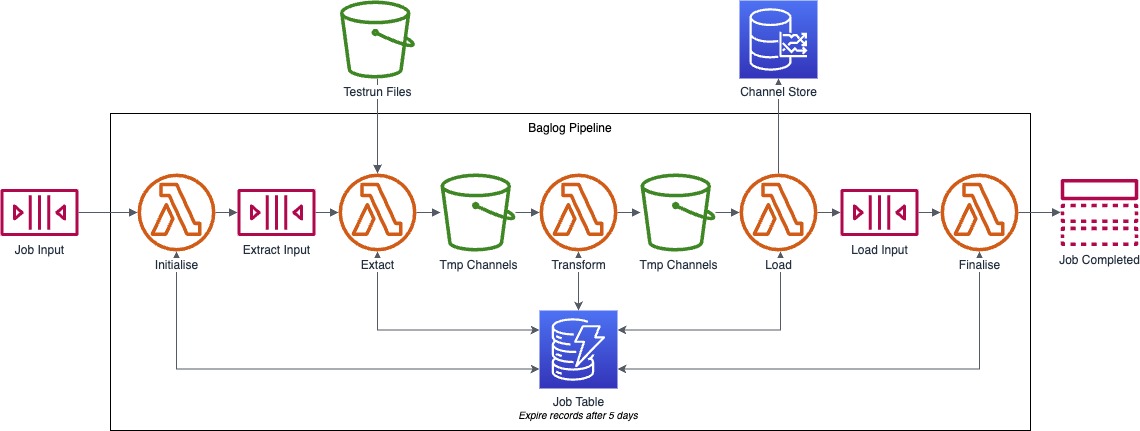
An alternative method to encode metadata is by using the S3 object's key. However, this approach is not recommended due to its limited extensibility and maintainability. Instead, we separate data related to a job's execution flow and data flow strictly. To that extent, we use a DynamoDB table to store a job’s metadata accessible by all Lambda functions (see Figure 6). As the job data can be temporary, we can leverage DynamoDB’s TTL feature to delete job records automatically. Adding the job table does not significantly impact the execution time and cost compared to the above values.
The last solution architecture (see Figure 7) uses architecture refactoring called Function Fusion. This merges or fuses a job’s stages into a single Lambda function. This approach has its own set of advantages and drawbacks. On the one hand, it helps us save costs and time by minimising the data transfer between Lambda functions. On the other hand, we may encounter limitations posed by AWS Lambda while executing functions with larger file sizes and greater computational complexities. While workarounds exist for some of these limitations, they can show up unexpectedly at runtime if neglected during the design.
For the single function solution architecture, we measure a runtime of 16 seconds and overall execution costs of 0.0004 USD.
We provide a short comparative assessment of the three solution architectures presented in the last section. Before a detailed comparison, we want to state again that the solution architectures provide additional features, and no extensive custom optimisations have been applied besides following best practices. Therefore, the exact numbers should be treated with caution. Nevertheless, the results indicate insights.
| Service Quality | Glue | Multi-Function | Single-Function |
| Job Run time [s] | ~180 | ~17 | ~16 |
| Job Cost [USD] | ~0.0700 | ~0.0005 | ~0.0004 |
The results indicate that custom solutions can significantly reduce job runtime and cloud costs. Thus, solution architectures should emerge from the business requirements of an application domain to balance options and limitations to the problem at hand.
Using the application example of vehicle testing from the automotive industry, we illustrated three options for building a data processing pipeline using serverless architectures and AWS cloud services. Serverless architectures offer many benefits but require careful planning and implementation to be effective. To achieve success, it's essential to have a deep understanding of various areas, such as the application domain, distributed systems engineering, data engineering, and cloud application engineering. These areas must be addressed to avoid unfulfilled promises and disappointing results.
Step into the future of serverless data-driven applications with DEMICON. Building on years of experience in all areas, DEMICON is ready to assist you on your serverless data-driven application journey.

Sie haben Fragen oder wünschen eine persönliche Beratung? Unser Experte hilft Ihnen gerne weiter.

1 min read
Imagine a leading automotive manufacturer on the verge of launching its latest model - a cutting-edge, software-defined vehicle (SDV) designed to...

In the whirlwind era of digital transformation, industries across the spectrum are awakening to the prowess of Data-Driven Applications. A key player...

Efficiency, transparency, and automation: How we optimize serverless architectures for financial services with a DevEx- and FinOps-driven approach.